Building a Serverless Control Plane for Redis Job Queues
How I replaced raw Redis queries in production with 11 Lambda functions, 5 Lua scripts, and a React dashboard. Built as my Bachelor's thesis in 10 weeks, deployed to production, used daily.
TL;DR
I built Queue Controller, a serverless REST API and React dashboard that replaced direct Redis queries in production with atomic Lua scripts, cursor-based pagination, and self-healing Lambda functions. The system managed hundreds of document generation jobs for a dozen clients on Pagination.com's automated document publishing platform. Built as a Bachelor's thesis in 10 weeks, deployed to production, used daily.
On this page
Context
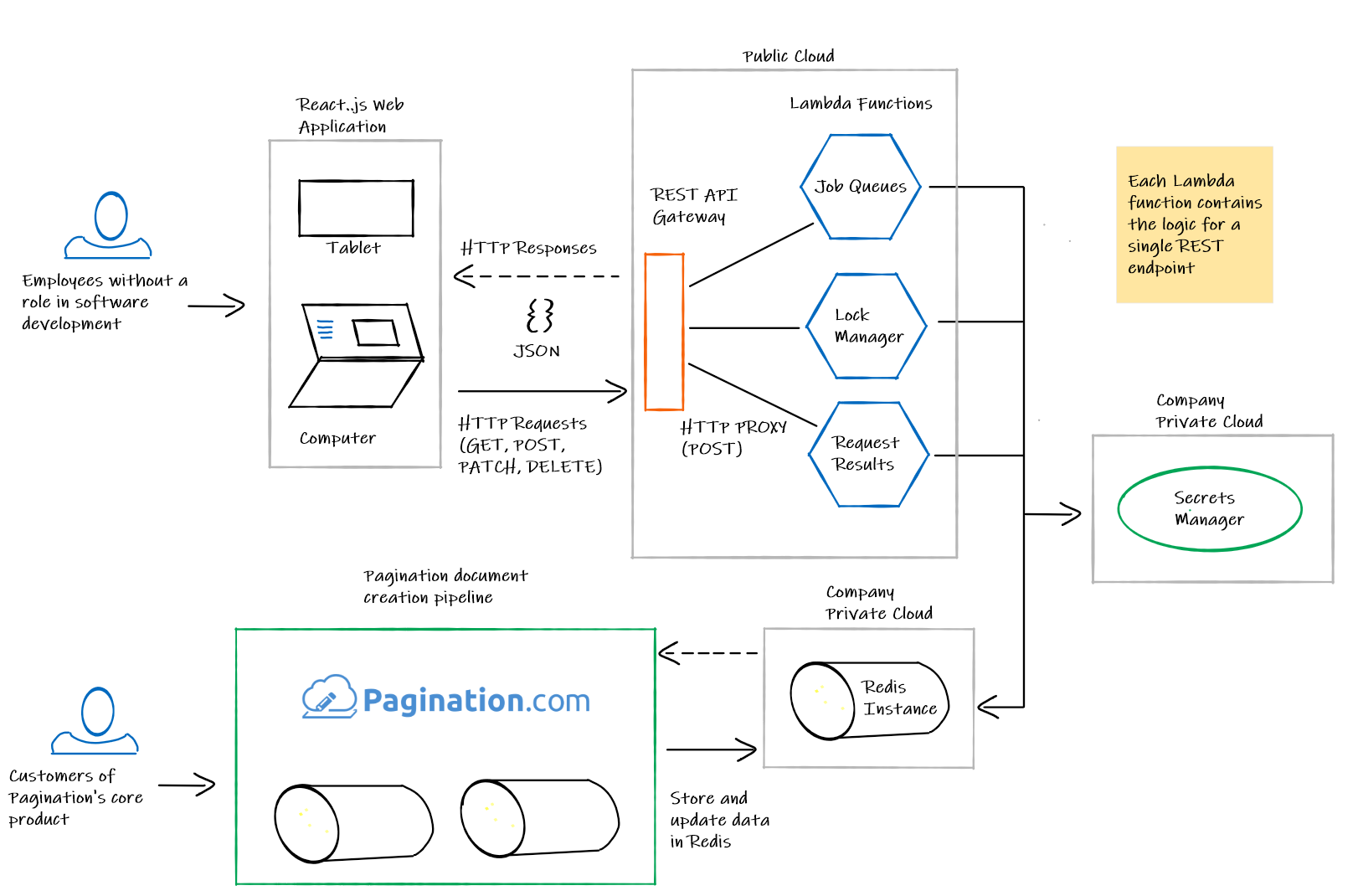
Pagination S.r.l. is a small company in Padova, Italy that turns raw data into professional documents. Clients like Fisher, Geox, and Prestashop upload spreadsheets, product databases, or CMS exports. Pagination generates catalogs, price lists, brochures, and technical documents as polished PDFs and InDesign files. A single catalog for a shoe manufacturer might contain 2,000 products across 300 pages; that entire document gets generated automatically from source data.
Behind the scenes, every generation request becomes a “job” in Redis. A single job might be split into smaller batches so the system can process parts of a large catalog in parallel. While a job runs, the system places a “lock” on the project to prevent concurrent modifications. Each lock carries a UUID token and a TTL (time to live) so that locks cannot be held indefinitely. At any given time, Redis held hundreds of jobs for roughly a dozen clients.
The Problem
Before Queue Controller existed, the operations team managed all of this by running Redis queries directly in production. The workflow: open an SSH connection, type commands against the live database, hope nothing breaks. The thesis described it plainly: “apparently simple operations like monitoring the pending pagination requests, unlocking a project or deleting a pagination job may only be performed by a technician. It’s a tedious project that involves opening multiple Secure Shell connections and manually running a number of commands against a Redis database instance.”
This was not just tedious; it was dangerous. Redis is single-threaded. A KEYS * command that scans the full keyspace blocks every other client until it completes. One technician running a careless query on a Monday morning could stall document generation for every customer simultaneously. Multi-step operations without atomicity compound the risk: a read-modify-write sequence that works fine when one person is typing commands falls apart when two Lambda functions hit the same keys at the same time. The data corruption is silent and the cleanup is manual.
Pagination needed two things: safe abstractions that made it impossible to accidentally block Redis, and a web dashboard that non-technical employees could use without SSH access or Redis knowledge.
What I Built
Queue Controller: a serverless REST API and React dashboard that replaced every raw Redis query with safe, atomic, paginated operations.
The backend runs as 11 AWS Lambda functions, one per endpoint, each wrapping a reusable Go library. Five Lua scripts handle every write operation atomically. Two iterator implementations traverse Redis data in pages without blocking the server. The frontend gives operators a visual dashboard where they can browse jobs, inspect individual splits in a JSON viewer, stop in-progress work, manage distributed locks, and delete stuck entries. The dangerous operations that previously required SSH and Redis expertise are now buttons in a web interface.
The infrastructure (API Gateway, Lambda, IAM, VPC networking) is defined in 50 Terraform files and deploys in a single command. A Jenkins pipeline handles CI with integration tests running against a real Redis instance.
I built this as my Bachelor’s thesis at the University of Padova during a 10-week internship at Pagination (320 hours, June 3 to August 9, 2019). I was the sole developer. My tutor at Pagination was Simeone Pizzi1; my thesis advisor was Dr. Armir Bujari. The project tracked 74 formal requirements; 72 were fulfilled at completion (97.3%). It shipped to production and was used daily.
Four Resources in Redis
Everything in Queue Controller revolves around four resource types and the Redis key naming scheme that connects them. The scheme is the conceptual foundation; without understanding it, the Lua scripts, iterators, and API endpoints make no sense.
Stage: "prod" Job ID: "abc123" jobs:prod:abc123 ← split list (Redis LIST) jobs:prod:abc123:count ← batch counter jobs:prod:abc123:additional ← metadata jobs:prod:abc123:stop ← stop signal (pushed on halt) prod:in-progress ← queue of active job IDs (LIST) prod:failed ← queue of failed job IDs (LIST) prod:deleted ← queue of deleted job IDs (LIST) prod:locks:project-42 ← lock with UUID token + TTL
A job is a document generation run. A split is one batch within that job, stored in a Redis list under the job’s key. A lock prevents concurrent access to a project; it carries a UUID token verified via an x-lock-token header, with a default TTL of 43,200 seconds (12 hours). A request tracks lifecycle state: in-progress, failed, or deleted.
Every key is prefixed by stage (dev/prod), creating complete data isolation between environments. This is a simple idea with an important consequence: an operator browsing production jobs cannot accidentally delete a development lock, and vice versa. The frontend includes a stage selector to switch contexts.
Atomic Operations with Lua Scripts
Here is the core engineering decision in the project, and the one I find most interesting in retrospect.
Redis write operations that touch multiple keys must be atomic. Without atomicity, a concurrent request can read stale data between steps of a multi-key mutation. This is not hypothetical: multiple Lambda functions serve concurrent API requests, all accessing the same Redis instance. Delete a job’s splits in one command and remove it from the in-progress queue in the next; between those two commands, another Lambda could read the in-progress queue, find the job, try to fetch its splits, and get nothing. The caller sees a job that appears active but has no data.
My tutor at Pagination explicitly mandated Lua-based atomicity: “operations that alter the Redis database state should be run as atomic operations via Lua scripts.” I already knew the pattern from Brainwise, my previous employer (2016-2019), where I had used Lua scripts for similar transactional Redis operations. Lua scripts are the only mechanism Redis offers for multi-key atomic transactions; they execute on the server side with guaranteed isolation.
Five scripts (136 lines total) handle every mutation. The most complex is deleteJob.lua:
-- Atomic job deletion: 6 Redis operations, one transaction
local stageID = KEYS[1]
local jobID = KEYS[2]
local stopJob = ARGV[1] == "true"
local splitsKey = "jobs:" .. stageID .. ":" .. jobID
local counterKey = splitsKey .. ":count"
local additionalKey = splitsKey .. ":additional"
local stopKey = splitsKey .. ":stop"
local inProgressKey = stageID .. ":in-progress"
local failedKey = stageID .. ":failed"
redis.call("DEL", splitsKey) -- remove split list
redis.call("DEL", counterKey) -- remove batch counter
redis.call("DEL", additionalKey) -- remove metadata
redis.call("LREM", inProgressKey, 0, jobID) -- dequeue from in-progress
redis.call("LREM", failedKey, 0, jobID) -- dequeue from failed
if stopJob then
redis.call("RPUSH", stopKey, -1) -- signal workers to halt
redis.call("EXPIRE", stopKey, 900) -- auto-cleanup: 15 min TTL
endSeven Redis operations, one atomic execution. Without Lua, a partial deletion could leave orphaned splits, a dangling counter, or a missed stop signal. The widget below lets you step through the script and see exactly what changes at each step. Toggle to “Non-Atomic” mode to see the race condition that Lua prevents.
In non-atomic mode (separate commands), each operation executes independently. Between steps, other processes can observe partial, inconsistent state.
The stop signal is a decoupled design worth highlighting. Queue Controller never directly halts a running worker; it does not own the Pagination service process. Instead, it pushes a sentinel value (-1) to a Redis list at jobs:{stage}:{jobID}:stop. The Pagination service polls that list in a Go select clause and halts if the signal is present. The 15-minute TTL on the stop key ensures automatic cleanup. Queue Controller communicates intent through Redis; it never touches the Pagination service’s internals.
These Lua scripts never exist as separate files at runtime. A custom build tool (tools/scriptgenerator) reads each Lua file, minifies it via LuaMinify, and embeds the result as a Go string constant via go:generate directives. The generated files live in pkg/*/generated/scripts.go. Lua source in, compiled Go binary out.
Reading Redis Without Blocking It
The alternative to KEYS * is SCAN: an incremental cursor-based command that returns results in small batches without blocking the server. The tradeoff is significant, and it took me a while to fully internalize it. SCAN cursors are opaque and forward-only. You cannot predict how many results each call returns (it varies per call, even with a COUNT hint). You cannot go backward. You cannot know the total count in advance. The cursor is not a page number; it is an internal hash table position that means nothing to the caller.
I wrapped this in an Iterator pattern with two implementations:
// The abstraction over heterogeneous Redis data structures
type Iterator interface {
HasNext() bool
Next(cursor int64, count int64) ([]string, int64, error)
Count() (int64, error)
}
// keysiterator uses SCAN for top-level key enumeration.
// listiterator uses LRANGE for ordered list traversal.
// Both satisfy Iterator. The caller never knows which
// Redis command runs underneath.keysiterator handles top-level key enumeration via SCAN with MATCH patterns and COUNT hints. listiterator handles ordered list traversal via LRANGE for resources stored in Redis lists (like job splits). Both satisfy the same interface. The API response includes a nextIndex that the client passes back to continue; which Redis command produces that index is invisible to callers.
This abstraction was not speculative. My tutor specified that the Redis structure “is extremely volatile and may change frequently. I should assume that the data currently stored in a Redis list may be moved to a Redis hash in a matter of days.” The Iterator interface was a defensive design against a known instability in the upstream system.
On the frontend, SCAN’s forward-only semantics created a real problem: how do you implement “Previous Page”? You cannot reverse a SCAN cursor. The answer is a client-side cache. PaginatedListCacheManager (215 lines of TypeScript, backed by 40+ test cases in a 719-line test file) stores previously fetched pages so backward navigation reads from local state instead of making impossible reverse-cursor API calls. Try it below: click “Next Page” a few times, then go back. Notice that backward navigation costs zero API calls.
Redis SCAN returns an unpredictable number of keys per call (here: 2-5). Cursors are opaque and forward-only. Click Next Page to issue SCAN calls. Previous Page reads from the client-side cache instead of making an impossible reverse-cursor API call.
The cache module is a layered abstraction. ListProxy delegates to a ListCacheFacade, which wraps PaginatedListCacheManager. A CacheIterator decorates the facade with forward/backward navigation flags. Three concrete pairs (Job, Lock, Request) bind the generics to domain types. The facade only hits the API when the cache misses; otherwise it returns from local state.


The Lambda Architecture
Each of the 11 REST endpoints maps to its own Lambda function, its own zip artifact, and its own Terraform resource. This Lambda-per-endpoint architecture was a client requirement: the core logic had to exist both as a reusable Go library (in pkg/) and as a Lambda handler wrapping that library (in cmd/). The pkg/ vs cmd/ split was contractual, not cosmetic. The core logic is cloud-agnostic; the Lambda layer is a deployment wrapper. If Pagination wanted to move off Lambda tomorrow, only cmd/ would change.
Lambda functions are “hot” between invocations: a function that started ten minutes ago might still hold credentials that have since been rotated. I dealt with this by writing a self-healing retry pattern:
// Lambda self-healing: retry with reinitialization
func HandleWithRetries(
initialize func() error,
handle func() (interface{}, error),
) (interface{}, error) {
result, err := handle()
if err == nil {
return result, nil
}
// First attempt failed. Credentials may be stale.
// Re-read SSM parameters, reconnect to Redis, retry once.
if initErr := initialize(); initErr != nil {
return nil, initErr
}
return handle()
}If the core operation fails, the function re-reads AWS SSM parameters, reconnects to Redis, and retries exactly once. No exponential backoff, no retry loop. One reinitialization attempt. If that also fails, the error propagates to the caller. This was the simplest correct thing I could think of, and it worked.
The architecture spans two cloud boundaries. Lambda functions run in the AWS public cloud behind API Gateway. Redis runs as an ECS instance inside Pagination’s private cloud (VPC). The Lambdas reach Redis through a VPC Gateway. Credentials are managed via AWS Secrets Manager (SSM), decrypted via KMS. This cross-VPC topology explains the SSM/KMS/IAM infrastructure in Terraform; this is not a simple “Lambda talks to Redis” setup.
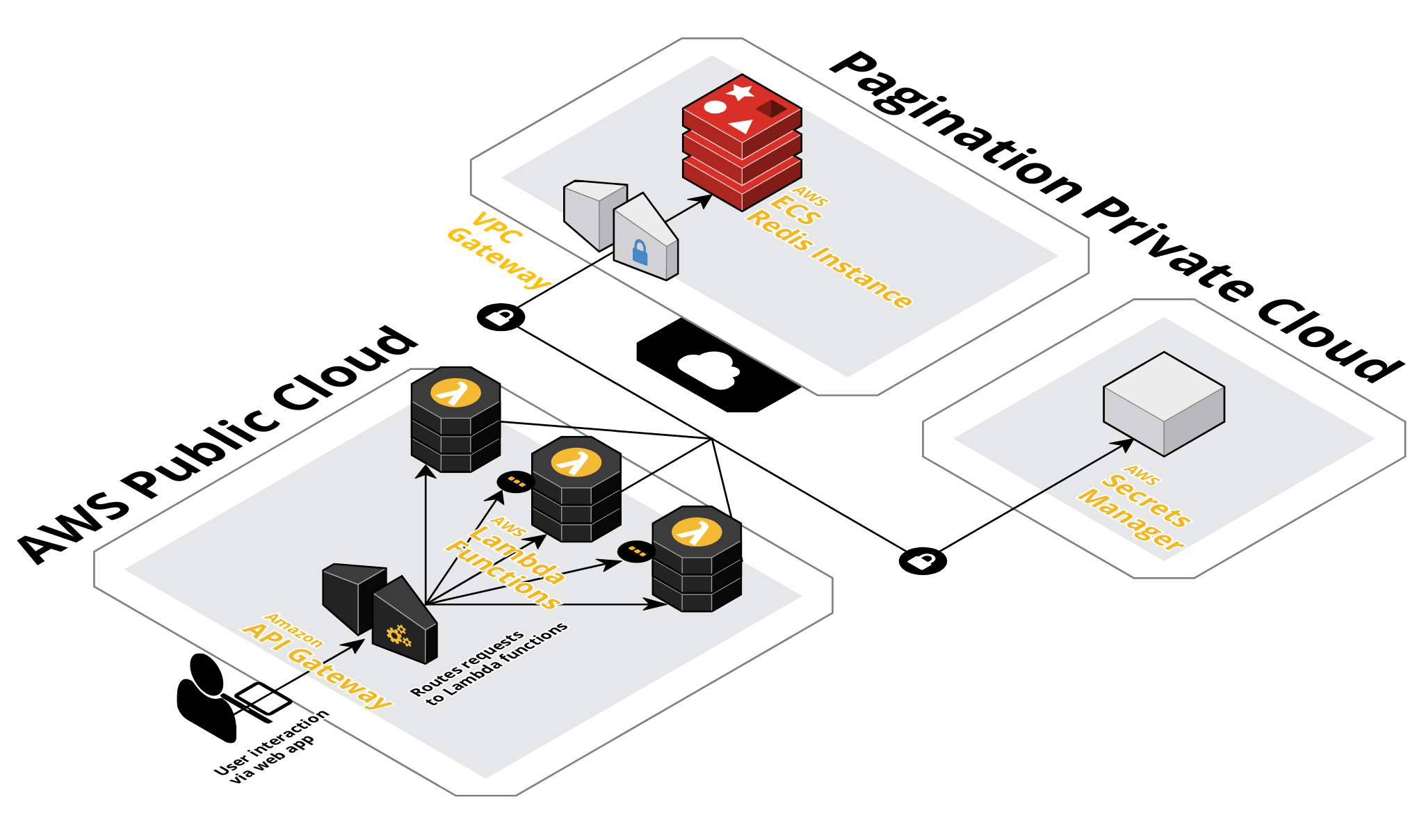
Protocol Buffers define all internal request models between Lambda handlers and core logic. The external API speaks JSON; the internal boundary speaks Protobuf. This was both a client request and a deliberate choice to keep serialization in an efficient byte format between layers the external user never sees. I had prior experience with Avro and Kafka; Protobuf felt similar.
The Build Pipeline
The CI pipeline involves more moving parts than the runtime architecture. A Docker builder image bundles Go, the Protobuf compiler, a Lua runtime, and LuaMinify. The build sequence: minify Lua scripts, run go:generate to embed them as Go constants, compile 14 .proto files to Go, build 11 Lambda binaries as statically linked Linux executables, package each as a zip artifact via build-lambda-zip.
Jenkins orchestrates this in a 5-stage scripted pipeline. Integration tests run against Redis 5.0.0 in Docker Compose. No mocks for Redis behavior; testing Lua scripts, SCAN cursors, and TTL behavior requires a real instance. I attempted Test Driven Development throughout; integration testing consumed more time than unit testing, but some modules reached 100% code coverage.
50 Terraform files define the full AWS infrastructure: API Gateway routes, Lambda configurations, IAM roles with KMS decrypt policies, SSM parameters, VPC networking. One terraform apply deploys everything. I found Jenkins painful (I had prior experience with Docker and Travis CI) but Terraform genuinely powerful.
The Dashboard
The React frontend provides three domain-specific views (jobs, locks, requests), a stage selector, and a tutorial for first-time users. Each view uses a split-pane layout: paginated list on the left, detail view on the right. Job details show split contents in a syntax-highlighted JSON viewer. Lock details show TTL countdown and token. Operators can stop in-progress work, delete stuck entries, create and release locks, refresh lock TTLs, and bulk-delete all locks in a stage.
A tutor constraint specified that “the web interface should be as clean as possible and its User Experience should be extremely intuitive, as it should be used by non tech-savvy employees.” The primary users were Pagination employees without a software development role. Tutorials, empty states, and toast notifications were requirements, not polish.
Honestly, the frontend was the least interesting part to build. Its value was not in the implementation but in its existence: non-technical employees could finally manage Redis infrastructure without opening a terminal.
What This Project Shows
The Redis iterator abstraction, designing a generic interface over heterogeneous data structures, is a direct precursor to my later work on database query engine abstractions at Prisma and contributing to Composio’s SDK. The Lua-script-for-atomicity pattern came from Brainwise and was brought to Pagination: cross-company knowledge transfer, applied to a different domain but the same underlying problem. The serverless architecture exploration, undertaken when AWS Lambda’s Go runtime was barely a year old (GA January 2018), led to my early adoption of Cloudflare Workers in 2021. Lambda cold starts were a tangible problem during this project; they motivated that later technology choice.
The thesis explored emerging serverless architecture patterns, which were still relatively novel in early 2019. The academic contribution included the iterator pattern for safely traversing arbitrary Redis data structures.
Ten weeks to design, build, test, deploy, and document a full-stack serverless system, as a thesis deliverable with 74 formal requirements, while being the sole developer. The codebase totals 114 Go files, 162 TypeScript/TSX files, 5 Lua scripts, 14 Protobuf definitions, and 50 Terraform files.
What I’d Do Differently
Add telemetry. No structured metrics, no dashboards, no distributed tracing. The only observability is CloudWatch Logs. If I rebuilt this today, exposing runtime telemetry would be the first investment. The system was “fast enough” because operators used it daily without complaint, but “fast enough” is not a number.
Benchmark cold starts. Lambda execution timeout was 2 seconds. Go’s garbage collection pauses within that budget were a genuine surprise. I have no p95 figures, no cold-start measurements, no cache hit rates. The tight timeout (EXEC_TIMEOUT_MS=2000) tells you cold starts mattered, but I cannot quantify how much.
Revisit the Jenkins pipeline. It worked, but it was painful. The build pipeline (Lua minification, Go code generation, Protobuf compilation, cross-compilation, zip packaging) involved enough moving parts that a simpler CI system with Docker-based stages would have been less fragile. Core backend and frontend features were done in roughly 6 weeks, along with some thesis writing; the remaining time went to Jenkins and Terraform. The CI/IaC investment was deliberate, but Jenkins specifically was the wrong tool.
Track adoption. The system shipped to production and was used daily. I cannot tell you how many operators used it, how many API calls it handled per day, or whether it reduced incidents. No usage analytics exist.